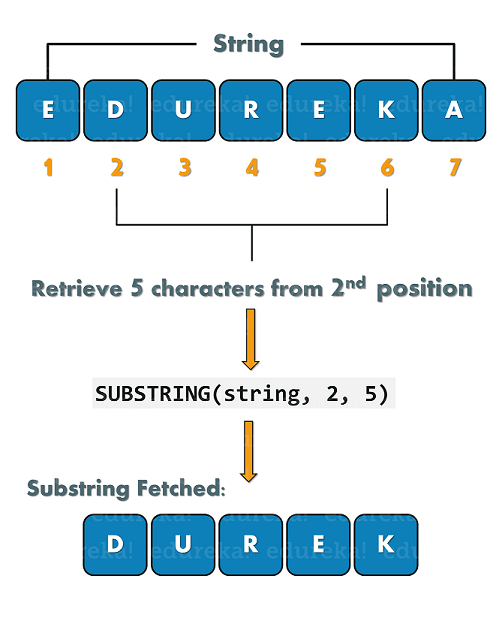
Tutorial HBase: Introducció a HBase i cas pràctic de Facebook
Aquest bloc d'aprenentatge HBase us presenta què és HBase i les seves funcions. També cobreix l'estudi de cas de Facebook Messenger per entendre els beneficis de HBase.

Aquest bloc d'aprenentatge HBase us presenta què és HBase i les seves funcions. També cobreix l'estudi de cas de Facebook Messenger per entendre els beneficis de HBase.
Aquest bloc és una guia sobre com instal·lar Puppet Master i Puppet Agent. També inclou un exemple per desplegar Apache Tomcat mitjançant el mòdul Puppet Tomcat.
Aquest bloc és una guia pas a pas per a la instal·lació d'Apache Pig a l'entorn Linux. Instal·larem Apache Pig 0.16.0 i l'executarem en diferents modes.
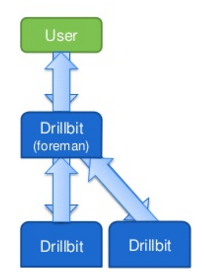
Aquest bloc sobre HBase Architecture explica el model de dades de HBase i dóna informació sobre HBase Architecture. També explica diferents mecanismes de HBase.
Aquest bloc d'aprenentatge Hive us proporciona un coneixement profund de l'arquitectura i el model de dades de Hive. També explica l’estudi de casos de la NASA sobre Apache Hive.
Aquest bloc de Spark Streaming us presentarà Spark Streaming, les seves característiques i components. Inclou un projecte d’Anàlisi de sentiments mitjançant Twitter.
Aquest blog Spark MLlib us presentarà la biblioteca d’Apache Spark’s Machine Learning. Inclou un projecte de sistema de recomanació de pel·lícules que utilitza Spark MLlib.
Aquest bloc Tutorial GraphX us presentarà Apache Spark GraphX, les seves característiques i components, inclòs un projecte d’anàlisi de dades de vol.
Aquest blog de tutorial d’Apache Flume explica els fonaments d’Apache Flume i les seves característiques. També mostrarà la transmissió de Twitter mitjançant Apache Flume.
Tutorial Apache Sqoop: Sqoop és una eina per transferir dades entre bases de dades relacionals i Hadoop. Aquest bloc tracta de la importació i exportació de Sooop des de MySQL.
Tutorial d'Apache Oozie: Oozie és un sistema de planificació de flux de treball per gestionar feines Hadoop. És un sistema escalable, fiable i extensible.
Les aplicacions de Big Data revolucionen les organitzacions i els ajuden a prendre decisions empresarials més informatives mitjançant l’anàlisi de grans volums de dades.
Apache Spark s’ha apoderat del món Big Data & Analytics i Python és un dels llenguatges de programació més accessibles que s’utilitzen a la indústria actualment. Així doncs, aquí, en aquest bloc, coneixerem Pyspark (spark with python) per treure el millor d’ambdós mons.
Aquest bloc se centra en Apache Hadoop YARN, que es va introduir a la versió 2.0 de Hadoop per a la gestió de recursos i la planificació de treballs. Explica l'arquitectura YARN amb els seus components i les tasques realitzades per cadascun d'ells. Descriu l'enviament de l'aplicació i el flux de treball a Apache Hadoop YARN.
En aquest bloc sobre el tutorial de PySpark, coneixereu l’API de PSpark que s’utilitza per treballar amb Apache Spark mitjançant el llenguatge de programació Python.
En aquest bloc de tutorial PySpark Dataframe, aprendreu sobre transformacions i accions a Apache Spark amb diversos exemples.
Aquest bloc Edureka sobre Cloudera Hadoop Tutorial us proporcionarà una visió completa de diferents components de Cloudera com Cloudera Manager, Parcels, Hue, etc.
En aquest post es descriu l’increment de la demanda d’habilitats Hadoop i NoSQL en els camps de la informàtica i altres. seguiu llegint per veure com us ajudaran les habilitats Hadoop i NoSQL
Aquest bloc tracta els avantatges de la implementació de Hadoop, les iniciatives de Hadoop, Hadoop en organitzacions petites i grans i els avantatges professionals de la formació de Hadoop.
Hadoop s’ha convertit en una gran habilitat que s’adquireix en el circuit de TI; el nombre d’alumnes d’Hadoop augmenta dràsticament dia a dia.